
About Sciscinet-v2
SciSciNet-v2 is a refreshed update to SciSciNet which is a large-scale, integrated dataset designed to support research in the science of science domain. It combines scientific publications with their network of relationships to funding sources, patents, citations, and institutional affiliations, creating a rich ecosystem for analyzing scientific productivity, impact, and innovation.
Linkages
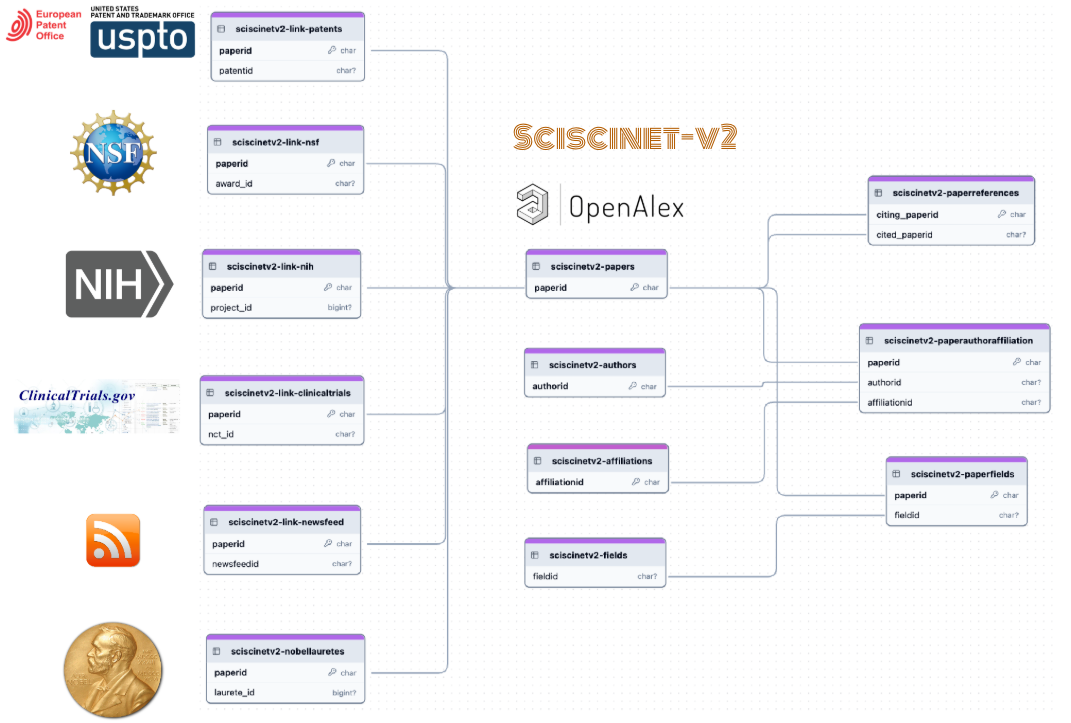
The entity relationship diagram for SciSciNet-v2. The dataset includes papers, authors, affiliations, and fields as the main entities in the center, with linkages to other tables capturing data from NSF, NIH, clinical trials, USPTO, EUPTO, NewsFeed, and Nobel Laureates on the left and the aggregation of main entity tables on the right.
Summary statistics
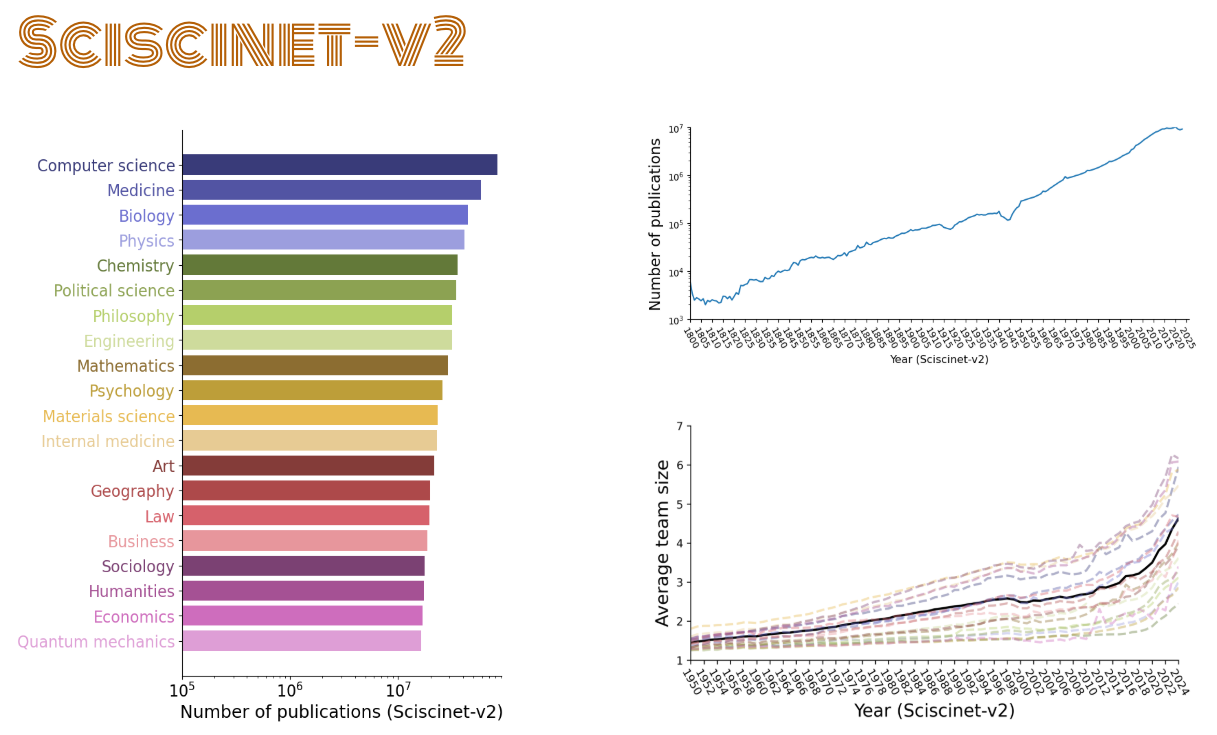
Summary statistics of scientific publications in SciSciNet-v2. (a) The number of publications in 19 top-level fields. For clarity we aggregated the field classification into the top level (e.g., a paper is counted as a physics paper if it is associated with physics or any other subfields of physics). (b) The exponential growth of science over time. (c) Average team size by field from 1950 to 2025. The bold black line is for papers in all the 19 top level fields. Each colored line indicates each of the 19 fields (color coded according to (a)).
Metrics
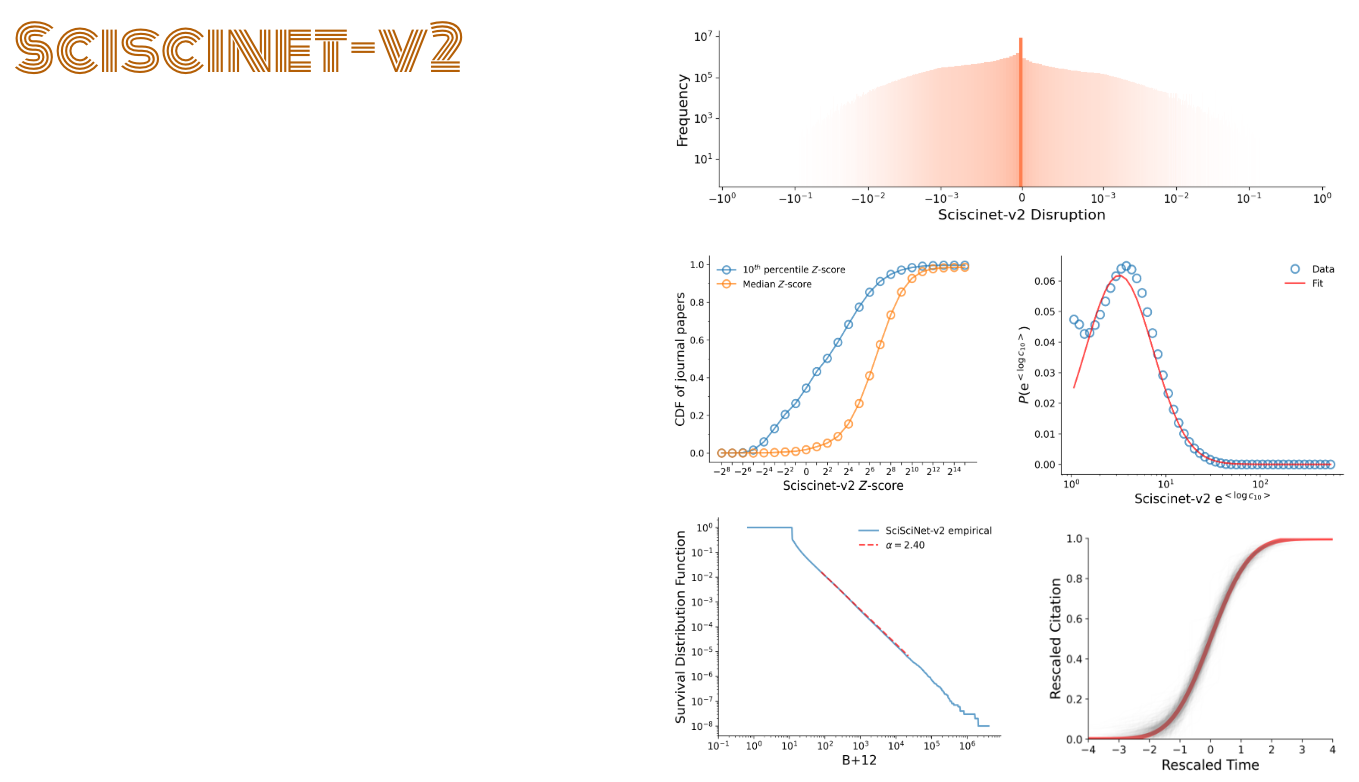
We re-calculated commonly used measurements at the publication level, citation dynamics, sleeping beauty co-efficient, novelty and conventionality, disruption score. We also re-calculated Individual and institutional level measures such as H-index, Scientific impact, Name-gender associations. We follow the same methodology from the original Sciscinet paper.
Embeddings for Paper, Title, Abstracts

More information
For more information about statistics, counts, FAQ's, how to access please visit the official website.
Official artifacts
Webpage: https://northwestern-cssi.github.io/sciscinet/
HuggingFace: https://huggingface.co/datasets/Northwestern-CSSI/sciscinet-v2
Team
Akhil Akella, Zihang Lin, Yifan Qian, Dashun Wang
Acknowledgement
This research was supported in part through the computational resources and staff contributions provided for the Quest high performance computing facility at Northwestern University which is jointly supported by the Office of the Provost, the Office for Research, and Northwestern University Information Technology.
This material is based upon work supported by the National Science Foundation under Grant No. 2404035. Any opinions,findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.