Context
This post is a continuation of an article, so it'd be ideal/nice if you read the first part of this post here: Tinker, smol-RL and QDoRA.
TLDR; (Part-1)
In Part 1, I showcase how reproducibility poses a practical problem in modern LLM work, not just a philosophical ideal. Even with greedy decoding and fixed seeds, determinism can break in subtle ways: GPU type, numerical precision, kernel choices, and non-deterministic log-probs in MoE models all conspire to make "run it again" less reliable than we like to admit. That led to a simple question: do we need a better abstraction layer so that the model ops complexity is hidden but the critical knobs for determinism are explicit and repeatable? Tinker reminded me of scikit-learn style API but for post-training models and the cookbook makes it easier to standardize the fragile pieces of post-training like reproducibility settings, dataset pre-processing, and stable training/inference pipelines. In Part 1, I talk about the Just-RL paper and how its a great starting point for testing Tinker's RLVR and RLHF setups on a small models before scaling data and model size.
Introduction
In this post, we will use the premise from the previous post to start with a small, practical Just-RL style setup and run it through Tinker's RLVR/RLHF abstractions to see what actually stays deterministic and what doesn't. I also plan to connect that to QDoRA in a small, controlled setting so the interaction between low-rank adaptation, precision choices, and stability is visible rather than hand-waved. In this post we will take a look at:
- a controlled RL-only sequence on single-turn disruption classification
- prompt changes, reward changes, and contract changes on a frozen split
- one RL follow-up (
Exp5) that tests class-weighted reward shaping
to-do:
- the planned QDoRA SFT baseline on the same task
- a real SFT-vs-RL comparison
- the Part 1 adversarial two-agent setup
- the joint disruption-plus-novelty objective
- the reproducibility sweep over dtype, hardware, kernels, or repeated runs
Data
The setup also matters because these runs do not begin from a generic instruction-tuning dataset. The broader corpus behind the disruption experiments is a SciSciNet/OpenAlex-style paper collection with 1,972,797 records. At the metadata level, each record can carry fields like openalex_id, title, abstract, publication_year, cited_by_count, cd_index, novelty_score, conventionality_score, disruption_label, novelty_label, primary_field, and concepts. For the actual RL experiments, though, I used a fixed JSONL slice: data/sci_balanced_from2m_no_ovr.rl_balanced.jsonl. A quick polars pass gives the main shape of that file:
>>> import polars as pl
>>> df = pl.scan_ndjson("data/sci_balanced_from2m_no_ovr.rl_balanced.jsonl")
>>> df.collect_schema().names()
['openalex_id', 'title', 'abstract', 'publication_year', 'cited_by_count',
'cd_index', 'novelty_score', 'conventionality_score', 'disruption_label',
'novelty_label', 'primary_field', 'concepts']
>>> df.select(pl.len()).collect().item()
600000
>>> df.group_by("disruption_label")
... .agg(pl.len().alias("n"))
... .sort("disruption_label")
... .collect()
shape: (3, 2)
┌──────────────────┬────────┐
│ disruption_label ┆ n │
│ --- ┆ --- │
│ str ┆ u32 │
╞══════════════════╪════════╡
│ consolidating ┆ 200000 │
│ disruptive ┆ 200000 │
│ neutral ┆ 200000 │
└──────────────────┴────────┘
>>> df.select(
... pl.col("publication_year").min().alias("min_year"),
... pl.col("publication_year").max().alias("max_year"),
... pl.col("cited_by_count").median().alias("median_citations"),
... pl.col("cited_by_count").quantile(0.9).alias("p90_citations"),
... pl.col("cited_by_count").max().alias("max_citations"),
... ).collect()
shape: (1, 5)
┌──────────┬──────────┬──────────────────┬───────────────┬───────────────┐
│ min_year ┆ max_year ┆ median_citations ┆ p90_citations ┆ max_citations │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ f64 ┆ f64 ┆ i64 │
╞══════════╪══════════╪══════════════════╪═══════════════╪═══════════════╡
│ 1875 ┆ 2024 ┆ 12.0 ┆ 90.0 ┆ 21559 │
└──────────┴──────────┴──────────────────┴───────────────┴───────────────┘
That small block already says most of what matters for interpreting the later runs. The file is not a toy benchmark, but it is also not the full upstream corpus. It is a balanced 600k slice with 200k examples per disruption class, and each example carries enough structure to be more than plain text: title, abstract, year, citation count, field, and the citation-derived disruption label. In practice, though, the runtime loader narrows this further and only uses the six fields that matter for the disruption task: title, abstract, publication_year, cited_by_count, primary_field, and disruption_label.
The important point here is that these labels are not arbitrary buckets I made up for the RL loop. The disruption labels come from citation-network behavior, and the novelty/conventionality fields come from how unusual or familiar a paper's reference combinations look relative to the background literature. Even though the current RL sequence only uses disruption_label, the wider corpus already carries the fuller science-of-science structure.
For disruption, the intuition is: what do future papers do after they cite a focal paper? If later work cites the focal paper without also citing its references, the focal work looks more disruptive. If later work keeps citing the focal paper together with the papers it built on, the work looks more consolidating. Values near the middle behave more like neutral. The figure below is the cleanest visual explanation of that idea from Wu, Wang, and Evans, Large teams develop and small teams disrupt science and technology.
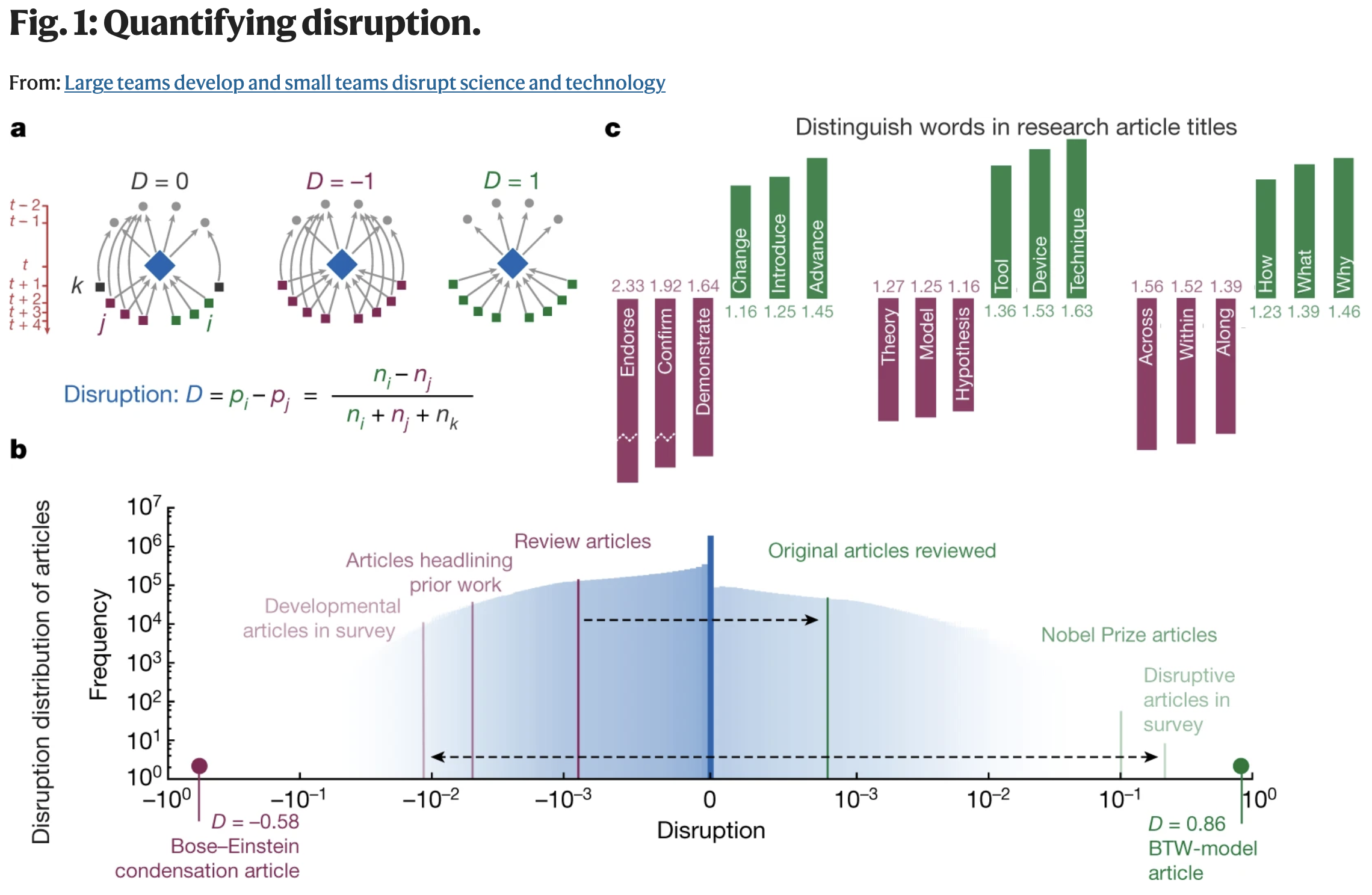
Fig. Reference view of disruption from Wu, Wang, and Evans, Large teams develop and small teams disrupt science and technology, Nature (2019).
That paper figure is the clean conceptual picture. For this post, though, the more useful question is: what does cd_index actually look like in the balanced JSONL that feeds the RL runs? The next plot recreates the panel b idea on the 600k slice used here. Two details matter. First, the slice is already balanced for training, so it should not be read as the natural frequency profile of the full 1.97M-paper source corpus. Second, the actual metadata thresholds in this dataset are much tighter than the older shorthand I used in Part 1: cd_index <= -0.001 is consolidating, -0.001 < cd_index < 0.001 is neutral, and cd_index >= 0.001 is disruptive. The tall spike at 0 is not a plotting bug; it is the empirical shape of the slice, where a large fraction of the neutral mass sits exactly at or extremely close to zero.
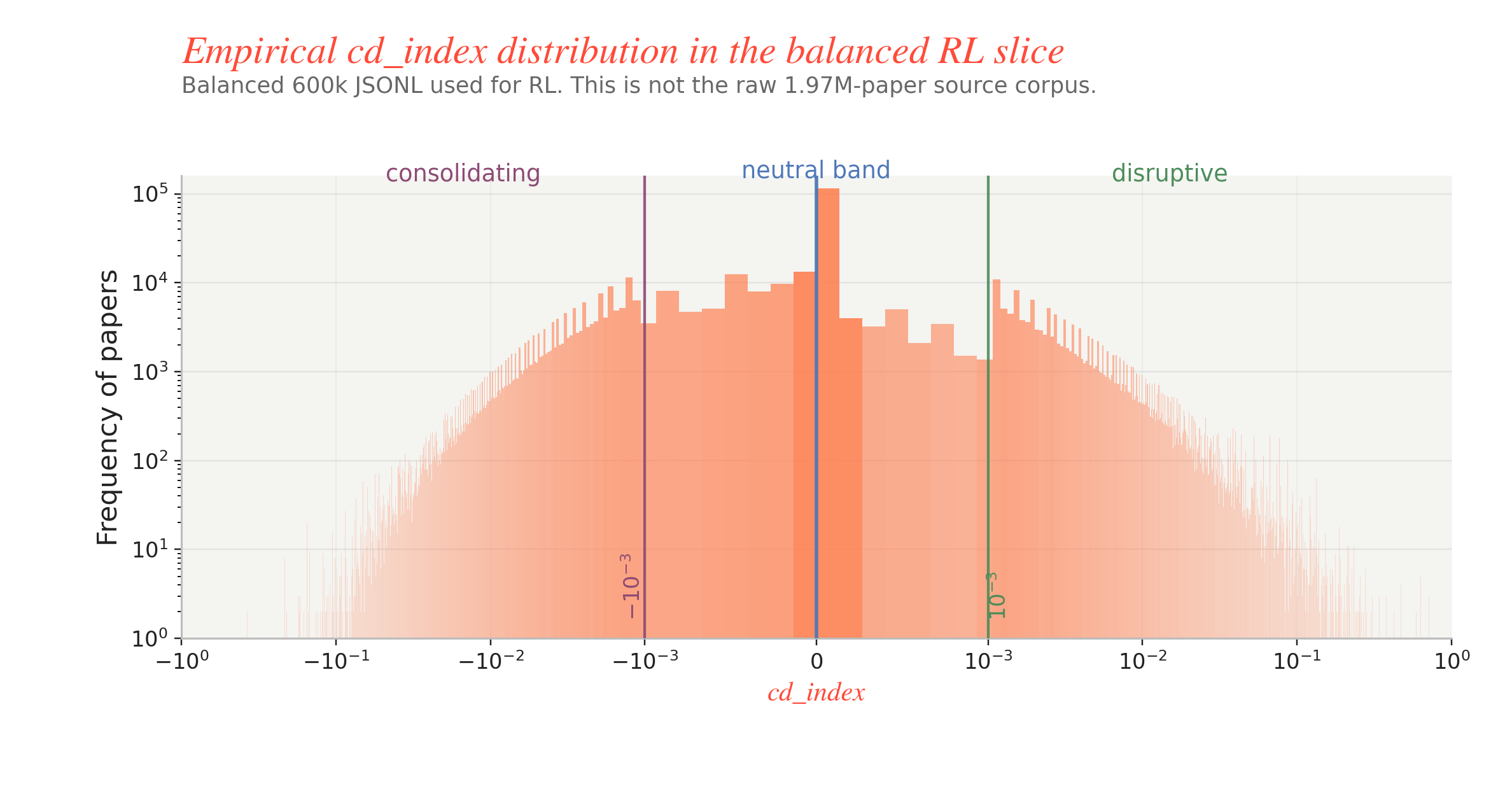
Fig. Dataset view of cd_index on the balanced 600k RL slice. The x-axis is shown on a signed log scale and the y-axis is paper frequency on a log scale; the shaded bands mark the dataset cutoffs for consolidating, neutral, and disruptive.
For novelty and conventionality, the logic is different. Here the question is not whether a paper overturns or develops prior citation pathways, but whether the combinations of prior work it cites are unusual or familiar. In the Uzzi et al. framing, the left tail corresponds to more novel combinations and the right side corresponds to more conventional combinations. That is why the corpus stores both novelty_score and conventionality_score: a paper can be mostly grounded in familiar prior work while still injecting a smaller amount of unusual combination. The figure below is from Uzzi et al., Atypical Combinations and Scientific Impact.
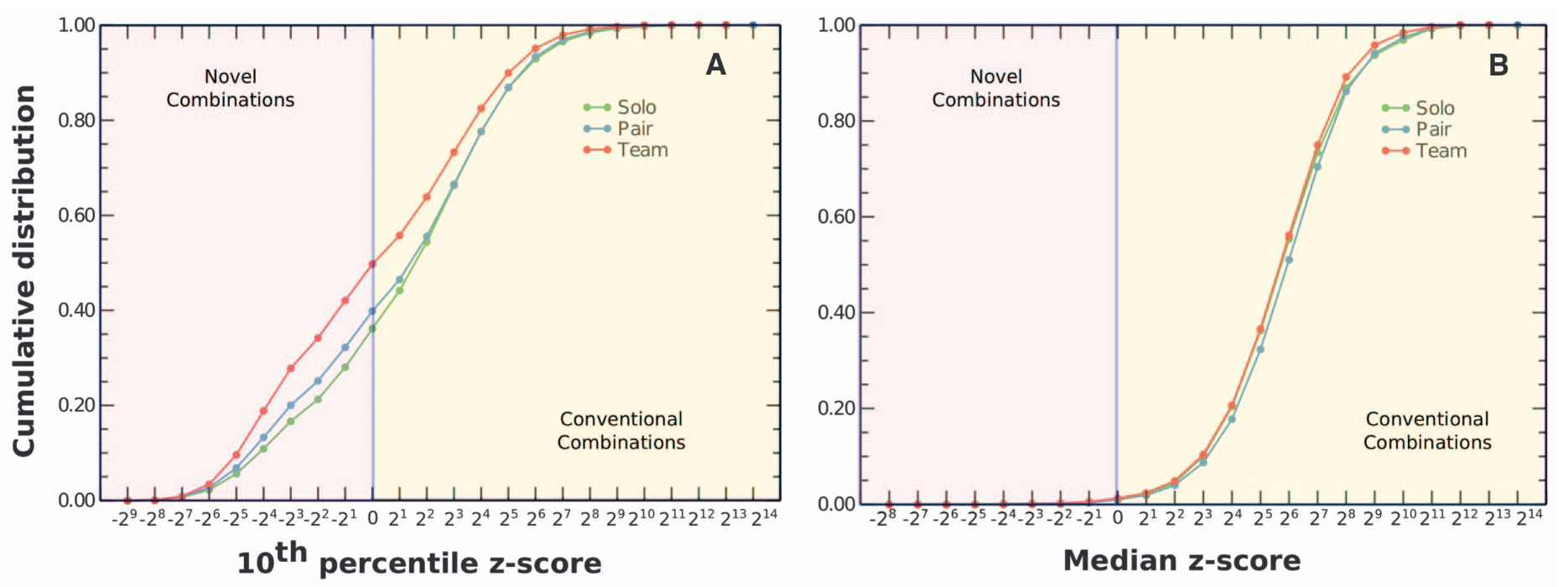
Fig. Reference view of novelty and conventionality from Uzzi et al., Atypical Combinations and Scientific Impact, Science (2013).
The broader provenance is still useful context. This balanced JSONL was carved out of a much larger SciSciNet/OpenAlex-style paper corpus with 1,972,797 records, where the raw disruption distribution is naturally skewed: about 247,090 papers are labeled disruptive, about 583,215 are consolidating, and about 1,142,492 are neutral. So the experiments here are not using the world as-is; they are using a balanced slice of a much more imbalanced scientific-impact distribution. That distinction ends up mattering quite a bit once the reward starts encouraging the model to exploit class asymmetries.
For the main four-run sequence, the loader then shuffles this JSONL with seed = 0, takes the first 5000 rows for train and the next 500 for test, and uses group_size = 2 for train versus group_size = 1 for eval. That sounds like a small implementation detail, but it is exactly the sort of detail that becomes important once the RL loop starts over-optimizing a proxy rather than learning the balanced classifier one might naively expect.
Experiment Frame
Before the charts, I need to say what these runs actually are, because otherwise Baseline, Exp1, Exp2, Exp3, Exp4, and Exp5 are just names on an axis.
Part 1 ended with a broader experimental agenda: Tinker, Just-RL, QDoRA, adversarial reasoning, novelty labels, and eventually an SFT-vs-RL comparison. The evidence below is narrower than that. Every numbered run in this section is an RL run on the disruption task only. The planned QDoRA SFT baseline belongs to the larger Part 2 program, but it is not one of the artifacts summarized here yet. The same goes for the Part 1 adversarial two-agent setup and the joint disruption-plus-novelty objective. Those ideas still matter, but they are not what the next tables and plots are evaluating.
The actual task here is much simpler:
$$ x_i = (\text{title}_i,\ \text{abstract}_i,\ \text{publication year}_i,\ \text{citation count}_i,\ \text{field}_i), $$
$$ y_i \in {\texttt{disruptive},\ \texttt{consolidating},\ \texttt{neutral}}. $$
Given a paper record $x_i$, the model emits a machine-readable prediction $\hat{y}_i$ as JSON, and the RL loop optimizes
$$ R_i = R_{\text{parse}} + R_{\text{contract}} + R_{\text{task}} + R_{\text{think}}. $$
In plain English, the reward has four moving parts: did the raw text parse as JSON, did it satisfy the required key/value contract, did it predict the right class, and did it avoid forbidden raw <think> output.
For the baseline and Exp1, the reward was intentionally soft on semantic mistakes:
$$ \text{valid + correct} = +0.75, $$
$$ \text{valid + wrong} = 0.0, $$
$$ \text{invalid payload} = -0.5, $$
$$ \text{raw JSON failure} = -1.0. $$
with an additional -1.0 penalty for raw <think> tags.
For Exp2, Exp3, and Exp4, the reward kept the same parse penalties but made label correctness matter much more:
$$ \text{valid + correct} = +1.05, $$
$$ \text{valid + wrong} = -0.55, $$
$$ \text{invalid payload} = -0.75, $$
$$ \text{raw JSON failure} = -1.0. $$
again with the same extra -1.0 penalty for raw <think> tags.
Exp5 is still RL, not SFT. It keeps the stronger Exp2-Exp4 reward shape, but multiplies correct disruptive predictions by 3x, so a valid correct disruptive answer can earn +3.05 while a valid wrong answer is still -0.55.
The other useful distinction is the output contract. Baseline through Exp3 asked the model for a richer four-key JSON object: disruption_label, label_justification, evidence_signals, and confidence. Exp4 and Exp5 cut that down to just disruption_label and confidence. That simplification turns out to matter a lot.
All of the runs below share the same fixed backbone: meta-llama/Llama-3.1-8B-Instruct, the same 5000 / 500 split, the same batch_size = 16, the same group_size = 2 for train, the same group_size = 1 for eval, and the same seed = 0. What changes from run to run is the prompt, the reward, or the contract.
That is the shortest run map:
| Run | type | change | i was testing for |
|---|---|---|---|
| Baseline | RL | reference run | whether the default contract + task setup was even usable |
Exp1 | RL | add explicit disruption-label ontology to the prompt | whether semantics were under-specified |
Exp2 | RL | strengthen the task reward | whether correctness pressure, not prompt wording, was the bottleneck |
Exp3 | RL | add decision checklist and mini examples | whether the disruptive vs consolidating boundary needed sharper calibration |
Exp4 | RL | shrink output JSON to two keys and cut max_tokens to 64 | whether contract simplification would recover reliability |
Exp5 | RL follow-up | keep the simpler contract, upweight correct disruptive predictions by 3x | whether a blunt class-weight fix could prevent disruptive collapse |
Eval Snapshot
With that structure in place, step 250 is the first checkpoint where Baseline through Exp4 are directly comparable on the same held-out 500 papers. The three views below are not the whole training story. Together, they are just the shortest way to answer one question: after 250 RL updates, did each run improve by learning the task better, or by finding a safer class bias?
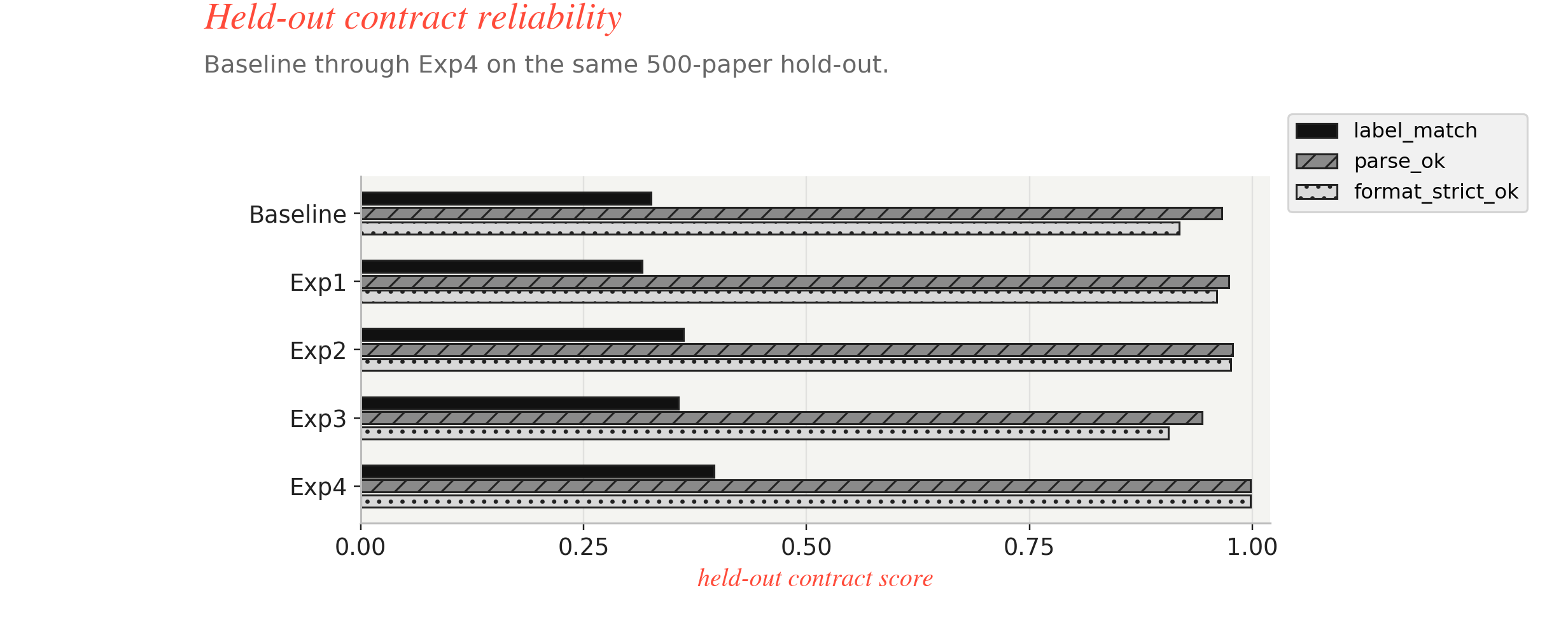
Fig. Output contract view across Baseline through experiment 4 checking label_match, parse_ok, and format_strict_ok.
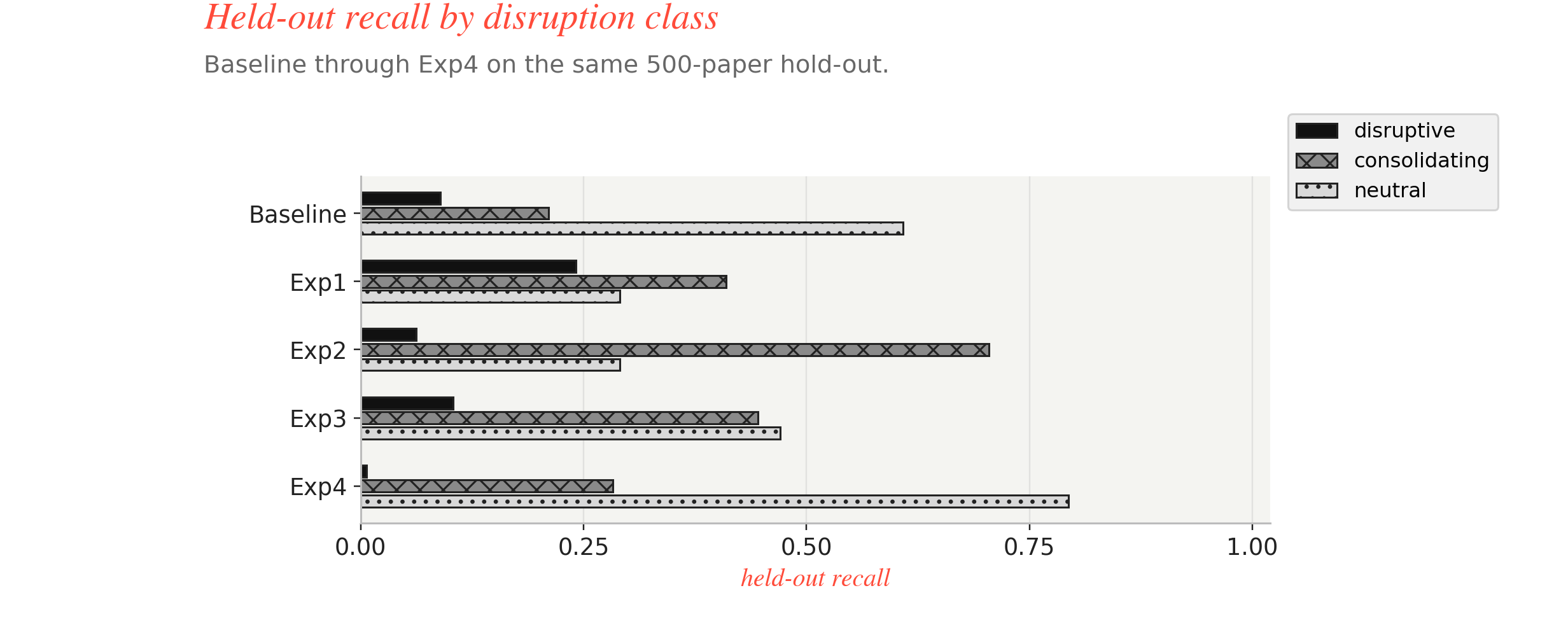
Fig: Class balance view across Baseline through experiment 4 checking recall on disruptive, consolidating, and neutral classes.
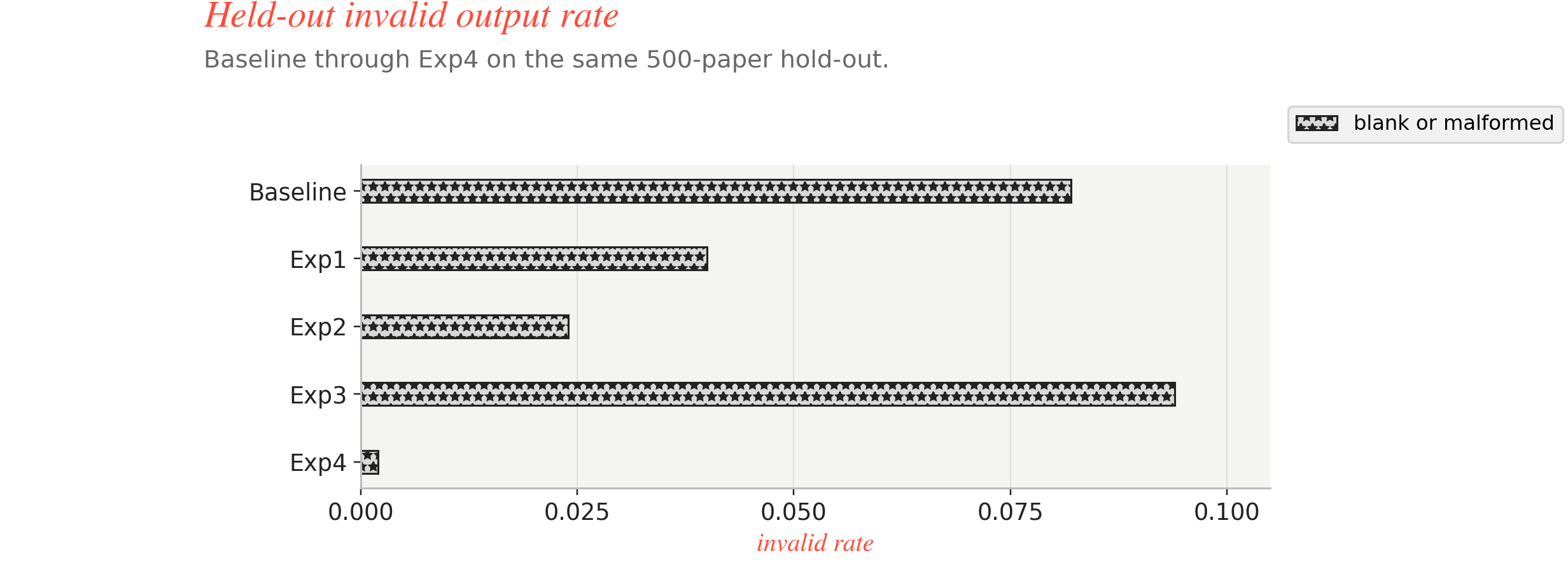
Fig: Reliability view across Baseline through experiment 4 to check invalid output rate.
| Run | Main change | label_match | parse_ok | format_strict_ok | disruptive recall | consolidating recall | neutral recall | invalid rate |
|---|---|---|---|---|---|---|---|---|
| Baseline | reference RL setup | 0.326 | 0.966 | 0.918 | 0.0897 | 0.2108 | 0.6085 | 0.082 |
Exp1 | ontology prompt | 0.316 | 0.974 | 0.960 | 0.2414 | 0.4096 | 0.2910 | 0.040 |
Exp2 | stronger semantic reward | 0.362 | 0.978 | 0.976 | 0.0621 | 0.7048 | 0.2910 | 0.024 |
Exp3 | boundary-calibration prompt | 0.356 | 0.944 | 0.906 | 0.1034 | 0.4458 | 0.4709 | 0.094 |
Exp4 | 2-key contract + max_tokens=64 | 0.396 | 0.998 | 0.998 | 0.0069 | 0.2831 | 0.7937 | 0.002 |
Read from left to right, the sequence makes a lot more sense now.
The baseline says the loop is operationally alive, but it is semantically conservative. It mostly hides inside neutral. Exp1 is the first real semantic move because the ontology prompt revives disruptive without breaking the contract. Exp2 proves that reward shaping can move the scalar metric, but it does so by leaning hard into consolidating. Exp3 gives up some contract hygiene to recover a more believable three-class boundary. Exp4 then solves the contract side almost perfectly, but it solves it while nearly erasing disruptive.
That is why the next sentence matters more than the top-line label_match: the runs are not all optimizing the same failure mode. Exp4 is the cleanest contract and the best raw step-250 scalar score. It is not the best balanced classifier. If I recompute held-out macro-F1 at step 250, the ordering is Exp3 ~ 0.337, Exp1 ~ 0.317, Exp2 ~ 0.309, Exp4 ~ 0.292, Baseline ~ 0.288. So the most reliable JSON checkpoint and the most balanced semantic checkpoint are not the same run.
If I’m being blunt, that is the whole problem in miniature. Once the parser stops being the main bottleneck, the policy finds easier ways to win the objective. So the next move after Exp4 is not "use a bigger model" or "add more output fields back." The next move is to fix the objective mismatch more directly.
Exp5: A Follow-Up, Not A Different Training Paradigm
This is exactly where Exp5 comes in. It is still an RL run. It is not the missing QDoRA SFT baseline. I ran it because Exp4 made the remaining failure mode too obvious: the contract was clean, but disruptive had effectively vanished. So the crude intervention was to say: fine, make correct disruptive predictions much more valuable and see what happens.
That gives the following held-out trajectory:
| Step | label_match | macro-F1 | predicted disruptive share | disruptive recall | min class recall |
|---|---|---|---|---|---|
0 | 0.3360 | 0.3003 | 0.0955 | 0.0823 | 0.0823 |
250 | 0.3445 | 0.2489 | 0.8295 | 0.8009 | 0.0132 |
500 | 0.3495 | 0.1819 | 0.9885 | 0.9928 | 0.0000 |
2000 | 0.3465 | 0.1716 | 1.0000 | 1.0000 | 0.0000 |
This is useful, but mostly as a negative result. At step 250, Exp5 can look superficially better if I only look at the rare class in isolation. Disruptive recall jumps from 0.0823 to 0.8009, and the contract remains almost perfect. But that is not a balanced classifier getting smarter. It is the policy discovering that the cheapest path to reward is to call almost everything disruptive.
The most revealing column in that table is not even label_match. It is predicted disruptive share. The run goes from 9.6% disruptive predictions at step 0, to 83.0% at step 250, to 98.9% at step 500, and then effectively 100%. So Exp5 is not a rescue of the Exp4 failure mode. It is the same reward-hacking pattern in the opposite direction.
That is actually a useful design lesson. A blunt class-weight bump is too coarse. It keeps the contract clean, but it just rotates the collapse. If I want a real frontier shift from here, the selector or the reward has to care about balanced behavior directly, not only about getting one neglected class back into the output stream.
References
1. https://arxiv.org/pdf/2402.03300
2. https://arxiv.org/pdf/2205.01833
3. https://arxiv.org/pdf/2402.09353
4. https://www.science.org/doi/10.1126/science.1240474
5. https://www.nature.com/articles/s41586-019-0941-9
Cite
@misc{akhil2026notesdrnote2,
author = {Akella, Akhil Pandey},
title = {Tinker, smol-RL and QDoRA (Part 2)},
year = {2026},
month = {February},
url = {https://akhilpandey95.github.io/notes/tinker_part2/},
note = {Accessed: }
}