Lately there is an surge in explosion of models, recipes and software libraries that are capable of doing deep research. The nature of what constitutes as a deep-research task would really depend on the person you're asking but its undeniable that any deep-research query is i.) agentic, ii..) long-horizon, iii.) large scale information seeking and iv.) information consumption workflow.
Deep-research agents can be used for various search directives, but they scour the information at a considerably high depth, gather the context of all of the crawled information into a final answer that hopefully gives valuable insights.[1]. Inherently, this is a huge time and effort saving exercise if the report generated in the end is of high quality.
Specialized models
The training behind DR Tulu is quite interesting because it is the first open-weight model that is post-trained using a new rubrics framework, or RLER as they describe it in their Github repo. To be very honest, the repository, blog and README in DR Tulu huggingface provide extensive information about the model and evaluation that its not worth it for me repeat the same information. Although, I personally feel the demo mentioned here gives you a sneak peek into final document quality. One of the cooler things you get to see in the demo page is the answers under section "SimpleQA", because typically people expect deep research agents to have incredibly verbose answers when the purpose can sometimes be channeled towards rolling out terse answers but searching deeply.
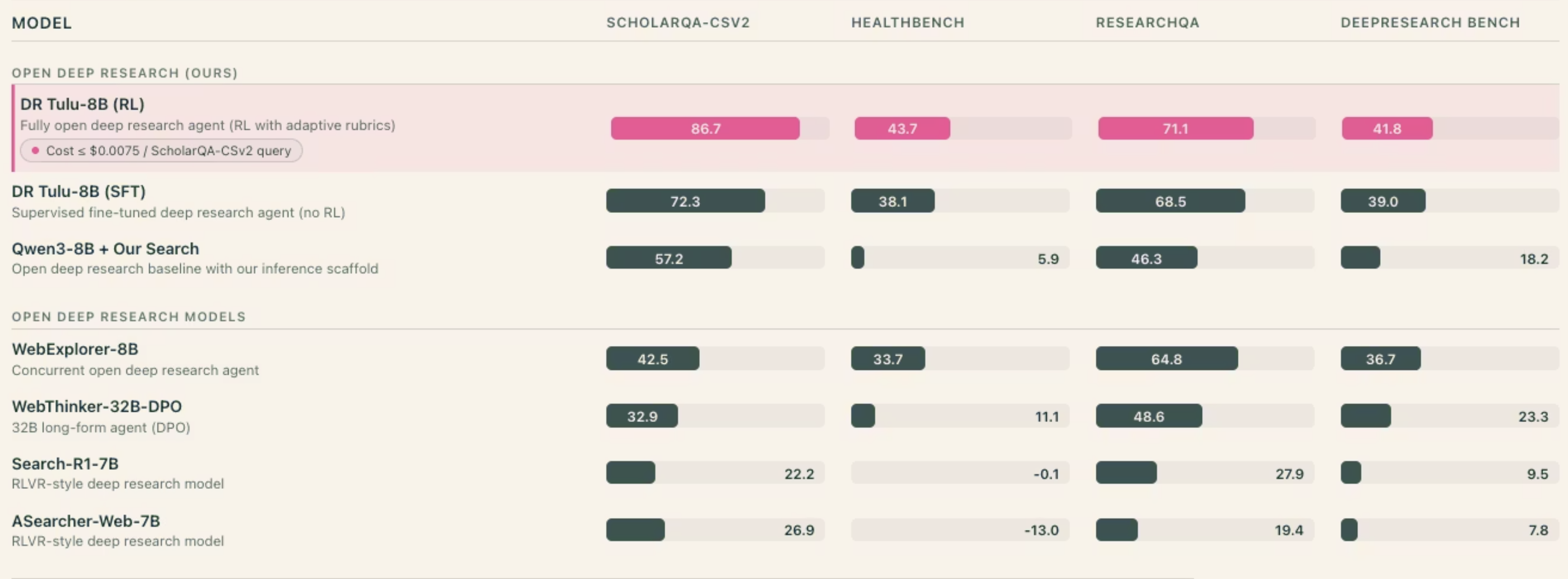
Fig 1. Open deep research model list observed from DR Tulu web annoucement page. Learn more
For those interested in quickly training a deep-research model that is similar to DR Tulu, the instructions here highlight that testing the setup using Qwen-3 0.6B on a single (assuming H100) gpu is possible.
Tongyi DeepResearch takes a different approach to the deep research problem. It's built on a Mixture-of-Experts (MoE) architecture with 30.5B total parameters but only 3.3B activated per token [5]. The training pipeline is elaborate: three distinct stages (Agentic CPT, SFT, RL) with a data synthesis framework called AgentFounder that generates training data from knowledge graphs. What stands out in their benchmarks is the performance on GAIA and AssistantBench--tasks that require multi-step reasoning across multiple sources. At inference time, you can switch between a lightweight ReAct mode for quick queries and IterResearch mode for thorough investigation, which feels like a practical acknowledgment that not every question needs the same depth.
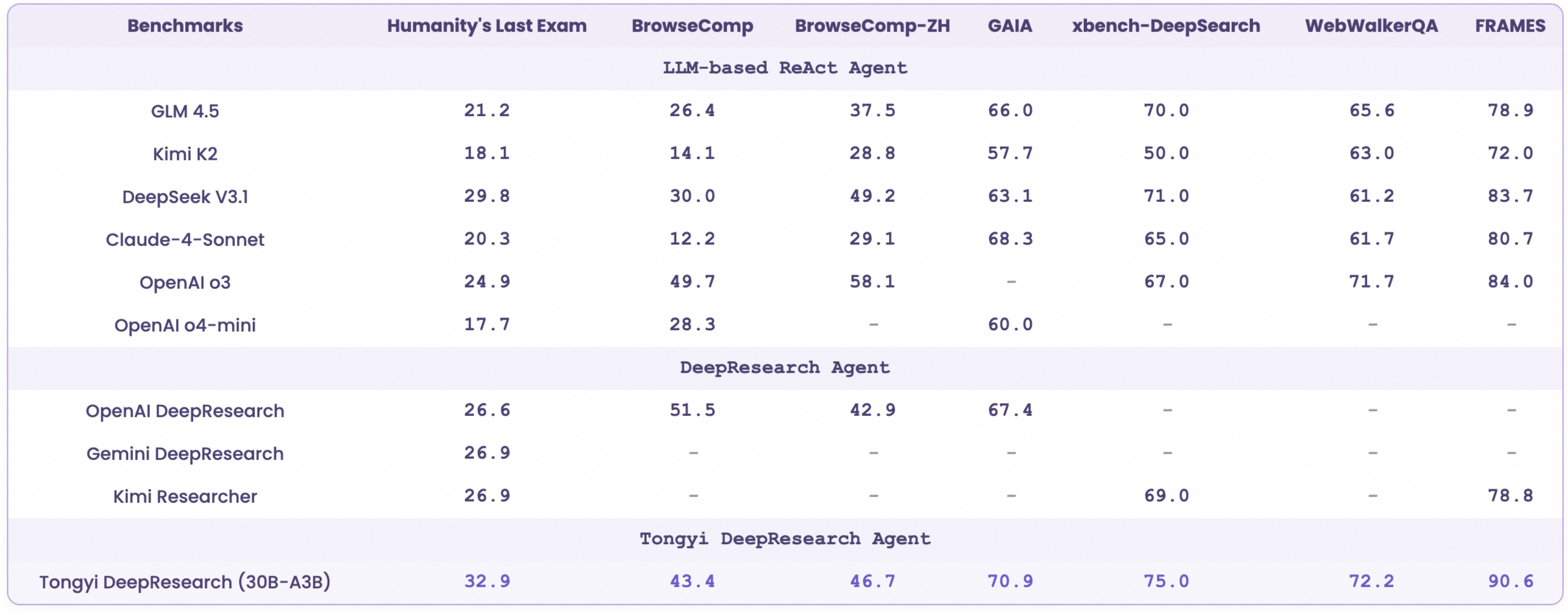
Fig 2. Tongyi DeepResearch agentic model benchmark results on several search benchmarks. More available
Kosmos from Edison Scientific is architecturally the most distinctive of the three. Rather than betting on larger context windows or more sophisticated prompting, they built what they call a "structured world model" a persistent, queryable database of entities, relationships, and open questions that survives across runs[6]. The system coordinates a data analysis agent and a literature search agent that share information through this store. The scale of operation is striking: a single research run can execute 42,000 lines of code and read 1,500 full papers. Their eval claims that one 20-cycle run was equivalent to 6 months of a human collaborator's research time[3]. Perhaps more provocatively, they claim four novel contributions to scientific literature emerged from Kosmos runs if that holds up under scrutiny, it's a meaningful shift from aggregation to generation.
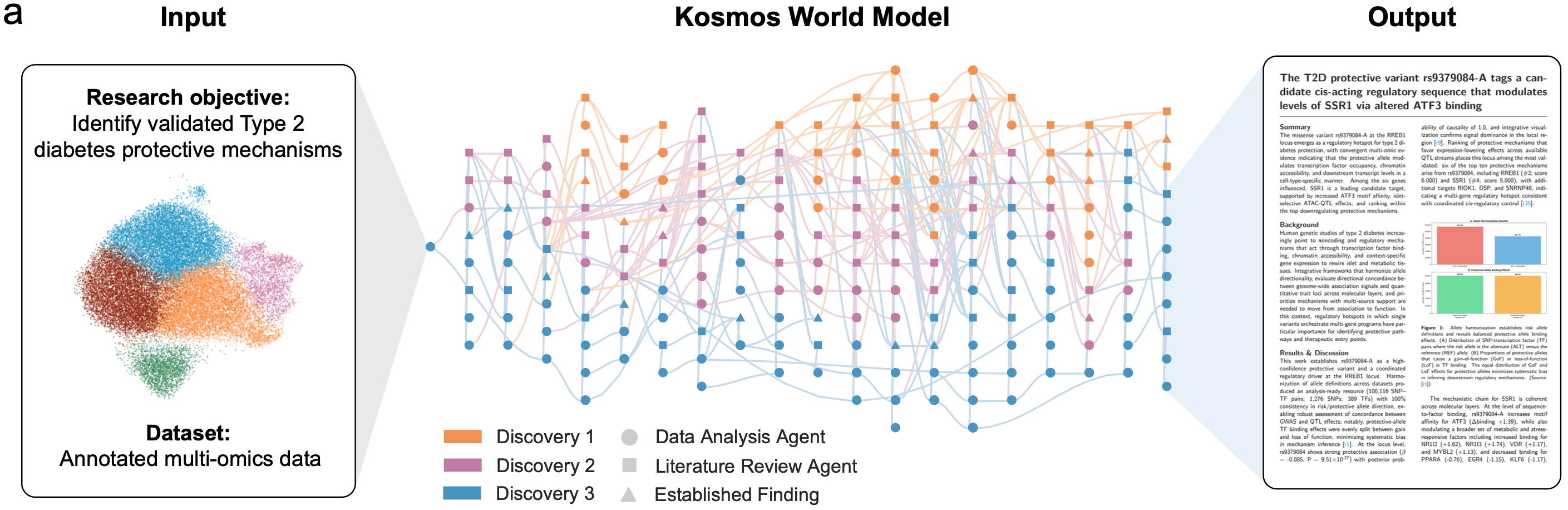
Fig 3. Input to output pipeline for a scientific world model involved in sophisticated autonomous discovery. More about Kosmos (https://edisonscientific.com/articles/announcing-kosmos)
Structurally, are they different tho ?
The appeal of a deep-research system comes down to how well it juggles searching, reading, and synthesizing. Looking at these three systems side by side, the philosophical divergences become clear.
While it can seem as the core tradeoff is between implicit knowledge vs explicit knowledge the RLER approach keeps evolving rubrics during training, dropping ones that hit near-zero reward variance because you don't need a large complex model here if your training signal (for this specific task obviously) is good enough. I think i was very firm on this notion that if you treat this abstraction of think, call_tool, cite, answer [4] as a protocol, then training a model (like DR Tulu) for this task seems to be pretty straight forward to achieve good results.
I guess operating with the above viewpoint made me question my core intuition when i noticed Tongyi's model since it takes the opposite intuition because the report suggests scale and efficiency are the right choices for a performant model. The three stage training pipeline (Agentic CPT, SFT, RL) suggests they view deep research capability as something that needs to be layered in progressively rather than emerging from a single training objective.
Now it might feel like I'm forcing in Kosmos into this discussion but if you give me a minute, I'd like to say that Kosmos sidesteps the above intuition entirely. Instead of asking "how do we fit more knowledge into the model?", they ask "why does knowledge need to live in the model at all?" The structured world model is essentially an admission that context windows are a fundamentally limited abstraction for research tasks. When you're synthesizing across hundreds of papers, you need something that persists and can be queried structurally. While Kosmos might be a commercial example of scientific product with structural difference on the appeal of a deep-research system, it's interesting is how these three examples align with different use cases.
DR Tulu's lightweight approach makes it accessible (1 gpu) and focussed on a straight forward task. Tongyi's model is more agentic and its work horse nature lets you match depth to task complexity while using the deep-research mode. Kosmos is overkill for simple queries but potentially necessary for scientific discovery or rather this promise of "scientific acceleration*. While this is not an classification encompassing all of the models/systems, these above three are definitely three interesting intuitions of a deep-research system that have an underlying abstraction thats possible to evolve.
Personally, I feel
As a researcher, the biggest cognitive boost I can receive is by having a reliable co-scientist capable of understanding my workflows for consumption (web), knowledge updates (memory), and selective recall of consumed information (skills) at frequent/infrequent intervals such that I can play a productive role in directing research rather than drowning in its logistics.
What excites me about the current landscape isn't any single model--its the patterns emerging across all of them. The Kosmos eval where a single 20-cycle run was equivalent to 6 months of a collaborator's research time[6] is cool, but how it gets there is cooler: a structured world model that just doesn't forget. This hits at what I think is my biggest bottleneck particularly, the cognitive overhead of re-establishing context every time I pick up a thread. To be honest, I spend a non-trivial amount of time re-reading papers I've already read, re-deriving conclusions I've already drawn, rediscovering connections I already made. A system with persistent, queryable memory feels less like a tool and more like an extension of my episodic memory that doesn't decay.
A convincingly written but wrong paragraph is arguably worse than no output, so I kinda like systems where I can trace where claims come from, so DR Tulu's explicit cite token and Tongyi's emphasis on faithful citations matter more to me than benchmark numbers. The ideal co-scientist for me would probably a frankenstein blend of Kosmos's structured memory with DR Tulu's citation first approach and Tongyi's inference flexibility. We're not there yet (or we are and I'm unaware), but all three being open-weight means the community can iterate toward that.
It would be fascinating and super scary to see these systems move from aggregation to hypothesis generation that actually surprises domain experts. Kosmos claims four novel contributions to scientific literature[3] and if these contributions really hold up, we're seeing the early stages of 2026 vibe-researcher / scientific acceleration phenomenon.
The idea of "deep" is evolving
Deep-research as a concept is evolving and abstracted into many interesting ways. Google's Gemini Deep Research[7] are some of the early examples of this evolving trend of deep agents powered by a strong foundational model capable on running long horizon tasks asynchronously through cycles of Plan -> Search -> Read -> Iterate -> Output. There are many variations of low-moderate level cognitive task that simply require longer horizons and this can be market analysis, scientific due diligence for drug discovery, carefull literature reviews for researchers to write a survey report/related work section in a paper, effectively any place where depth matters more than latency.
Also, its worth noting that open software SDKs/platforms are quickly converging on this notion because back in July'25 Deep Agents[8] was launched effectively giving proper software scaffolding for abstracting the idea of deep-agents. Ideally, its easy to have seen this coming given major strides (i mean culturally) in 2025 have come from gemini deep research, TUIs (claude code, codex), manus computer use agents and several other agentic products. deepagents package simply packages these into a reusable software scaffolding/harness with write_todos for task decomposition, file system tools (ls, read_file, write_file, edit_file) for offloading context to disk, and a task tool for spawning specialized subagents with context isolation.
Most crucial emerging pattern i observe here is, deep-research being less about a single model (or) chat platform offering a button with "deep-research" but a gateway into a more sophisticated interaction pattern (or paradigm maybe). This slowly gives us a speak into 2026 on how enterprise software is going to reign in on long runnign agentic tasks; Long-running async execution, explicit planning phases, external memory stores, spawnable sub-agents. While its hard to see if open-source/open-weight efforts like DR Tulu, Tongyi will catch up to this evolving abstraction, a relevant point here is the seamless interchangable nature of "deep research" will practically define "what is a useful LLM?" into something that can actually do research rather than just answer questions about research.
References
1. https://allenai.org/blog/dr-tulu
2. https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
3. https://edisonscientific.com/articles/announcing-kosmos
4. https://arxiv.org/abs/2511.19399
5. https://arxiv.org/abs/2510.24701
6. https://arxiv.org/abs/2511.02824
7. https://ai.google.dev/gemini-api/docs/deep-research
8. https://blog.langchain.com/deep-agents/
Cite
@misc{akhil2025notesdrnote1,
author = {Akella, Akhil Pandey},
title = {What is it about these Deep research models lately?},
year = {2025},
month = {November},
url = {https://akhilpandey95.github.io/notes/dr_note1/},
note = {Accessed: }
}