Graphs and LLM's
The evolving nature of experiments in artificial intelligence and the exponential pace of scientific progress in developing domain specific large language models (LLM) elevated the use cases of language models to assist researchers in advancing scientific discovery. Conversational interfaces using Auto-regressive LLM's such as GPT-4, LLaMA, Gemini, Claude, Mistral dominated the public discourse with immediate adoption by diverse communities. Knowledge distillation from representations of LLM's are good priors for evaluating predictive models large for AI for Science(AI4Science) initiative and scientific discovery in the age of artificial intelligence will rely on such initiatives. Scientific discovery includes several stages and collecting the data, building the experiments, analyzing the results to come up with salient hypothesis are few of the stages that have reasonable scope to include LLM's in the loop. Augmenting various stages of the scientific process with AI models comes with a plethora of benefits and poses risks therefore it is important to make reliability, and safety of these models a priority thereby enhancing the societal benefit of scientific discovery.
Interesting research directions
Science is an ongoing process and the rapid evolution of artificial intelligence, particularly large language models (LLMs), has profound implications for scientific discovery [4]. We need to ensure models utilized for scientific problems such as navigation in the hypothesis space of scientific data, predictive modelling on protein sequences etc must have trust and safety principles embedded within architecture considerations. To fully align with AI4Science initiatives, it is critical to prioritize reliability and safety, ensuring societal benefits. The agenda for my future research builds on the foundations of representation learning, graph theory, and transformers to build an empirical framework for accelerating scientific discovery. This research agenda transcends mere scholarly inquiry. The outcomes of my future research will focus on developing a large-scale computational framework bringing together Transformer language models (Pre-trained & Auto-regressive), Representational learning techniques (Geometric & Sequential), and uncertainty quantification approaches. This framework aims to accelerate scientific discovery and conceptually, ideas mentioned in [1], and [2] as observed in Fig. 1. provide recipes for the responsible application of AI models throughout the scientific process.
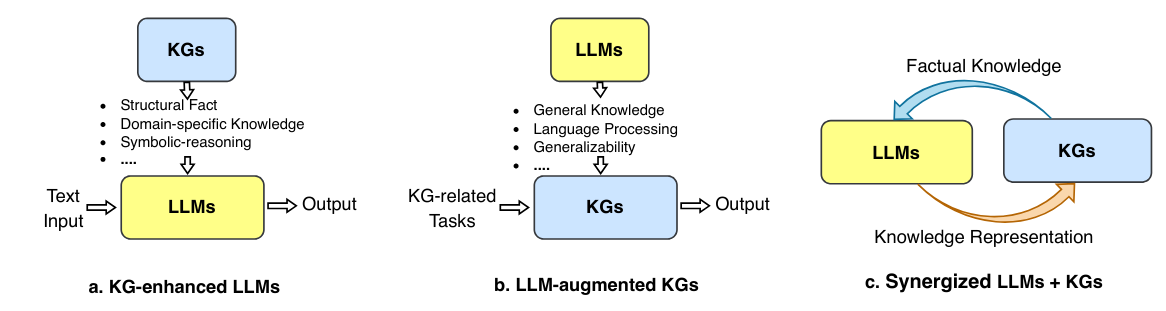
Fig 1. A generalized roadmap to unify heterogenous graphs with large language models as mentioned in [2].
Learning meaningful representations of scientific data
The foundation of effective AI support in science lies in the ability to represent complex scientific data in ways that are both meaningful and computationally tractable. This direction will investigate advanced representation learning techniques to capture the nuances and relationships inherent in scientific knowledge. Eq.1 represents the pseudo-likelihood variational framework 5. that will be useful for learning node level representations when we combine GNNs and LM's together in Text Attributed Graphs represented by
$$\mathcal{G} = (V, A, s_V)$$
where for all nodes $V$ and their adjacency matrix
$$A \in \mathbb{R}^{|V| \times |V|}$$ each node
$$n \in V$$
is associated with a sequential text feature (sentence), giving us Eq.1
$$log p(y_i | s_i, A) >= E_{q(y_i' | s_i')} [log p(y_i' | s_i, A) - log q(y_i' | s_i')]$$
Uncertainty Aware fused Graph-Language models for scientific discovery
Quantifying uncertainty in mission critical scientific applications often brings challenges with respect to model architecture and training procedures. Building uncertainty-aware synergized graph-language models will seamlessly blend graph-based representations with language model embeddings, allowing for explicit modeling of uncertainty and supporting more robust scientific reasoning.
The first part of Eq.2 represents using LLM's to obtain contextualized embeddings for text data associated with the nodes in a graph where
$$\mathbf{x}_i$$ is the input text sequence associated with node i,
$$\theta_\text{LM}$$ are the parameters of the language model, and
$$\mathbf{h}_i$$ are the contextualized embeddings obtained from the language model for the input text
$$\mathbf{x}_i$$
$$\mathbf{h}_i = LM(\mathbf{x}_i, \theta \text{LM})$$
$$q(\mathbf{z}_i) = \mathcal{N}(\mu_i, \sigma_i^2)$$
By modeling the fused representation $\mathbf{z}_i$ as a distribution rather than a point estimate, the model can capture uncertainty in the representations. As an under-explored concept, it would be interesting to bring various UQ estimation techniques employed for Graphs [3] onto fused graph-language models.
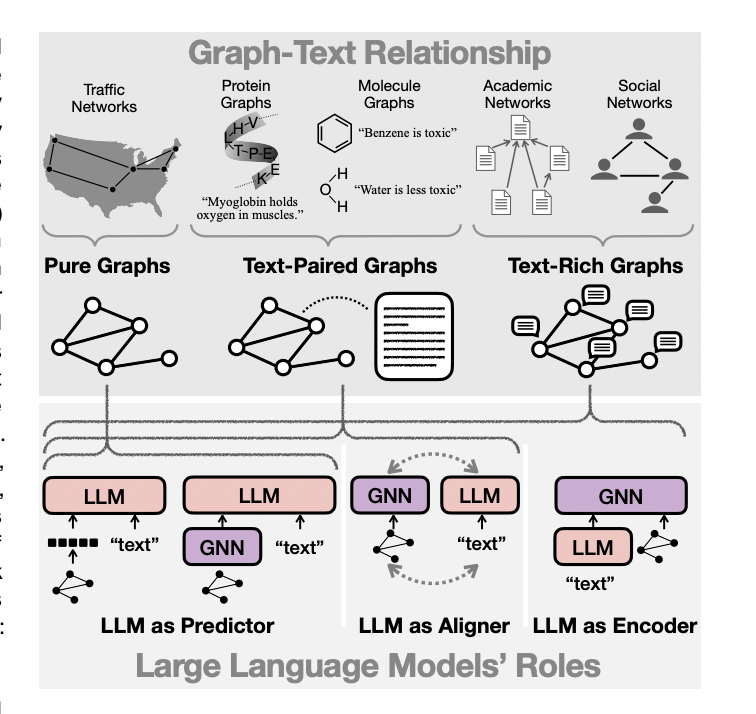
Fig 2. Possible directions exposed in [1] on utilizing LLM's on graphs with varying degree of textual information
Efficient utilization of semantic neighbors for generating scientific hypotheses
Generating Scientific hypothesis is a novel task in the list of grand problems potentially addressed by AI for scientific discovery [4]. This direction will explore strategies for leveraging the rich neighborhood information in the form of semantic neighbors, citation neighbors, and knowledge neighbors within scientific literature to facilitate efficient and insightful hypotheses that will be beneficial for the research community.
Broader Impact
The broader impact of my research is to contribute towards furthering the discussion on methods to enhance scientific discovery that can potentially affect the general public, and scholarly communities. Addressing scientific novelty and and facilitating impactful knowledge discovery will save human capital, intellectual capital, time, and computational resources. My work can serve as a means to amplify calls for a robust, transparent, and trustworthy scientific environment. By advancing theoretical knowledge and practical methodologies, I aim to influence the broader scientific community's approach to research integrity. Additionally, through my publications, I am committed to disseminating my findings and fostering a dialogue, aiming to raise awareness and encourage best practices within and beyond the academic community.
References
- Jin, B., Liu, G., Han, C., Jiang, M., Ji, H., & Han, J. (2023). Large language models on graphs: A comprehensive survey. arXiv preprint arXiv:2312.02783.
- Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., & Wu, X. (2023). Unifying large language models and knowledge graphs: A roadmap. ArXiv, abs/2306.08302. Retrieved from https://api.semanticscholar.org/CorpusID:259165563
- Wang, F., Liu, Y., Liu, K., Wang, Y., Medya, S., & Yu, P. S. (2024). Uncertainty in graph neural networks: A survey. arXiv preprint arXiv:2403.07185.
- Wang, H., Fu, T., Du, Y., Gao, W., Huang, K., Liu, Z., . . . others (2023). Scientific discovery in the age of artificial intelligence. Nature, 620(7972), 47–60.
- Zhao, J., Qu, M., Li, C., Yan, H., Liu, Q., Li, R., . . . Tang, J. (2022). Learning on large-scale text-attributed graphs via variational inference. arXiv preprint arXiv:2210.14709.